
又是深度强化学习?
Curly的四个小轮子排成U形,前轮用于抓住冰壶,它们由传送带提供动力,传送带使冰壶旋转,就像人类玩家的操作一样,当沿顺时针旋转时,冰壶会向右卷曲;逆时针旋转则向左。
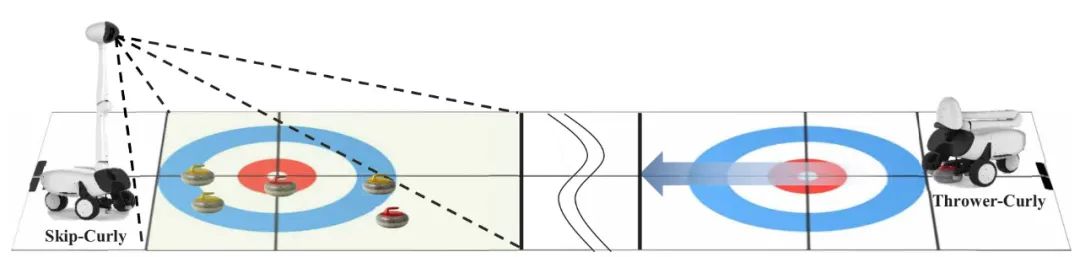
Curly的程序完全通过电脑游戏来进行训练,和很多「人机大战」的技术一样,Curly使用的也是「深度强化学习技术」,这能在程序边纠正自己的错误边改进。

深度强化学习在很多决策领域当中都取得了比较不错的结果,尤其是在游戏,多个游戏已经达到甚至是超过了人类水平。基于深度强化学习,DeepMind研发的AlphaGo Zero在不使用任何人类围棋数据的前提下,在围棋上完虐人类;OpenAI研发的Dota Five则在Dota游戏上达到了人类玩家的顶尖水平;DeepMind研发的AlphaStar在星际争霸游戏上同样击败了人类职业玩家。
3:1!Curly赢了职业选手
在训练时,冰壶和冰都是用物理模型来模拟的。这样,研究人员就可以观察训练的情况如何,当然,这取决于模型的精准性。结果证明,训练的效果非常好,Curly只需要在每一场比赛的开始投一次冰壶,就能熟悉不同的情况,比如冰面是否足够光滑让冰壶划走。

Curly果然不负众望,在四轮比赛中赢了三场。但也有人发出质疑,如果加入擦扫冰面的条件出现,但对于一个机器人来说,这个成就已经非常值得骄傲了。研究人员指出,这是一项重要的成就,不仅因为这证明了机器人在这项运动中具有竞争力,这项研究也涉及未来现实世界中实时的动态观察和决策。因此,对于AI和机器人而言,这都是一个里程碑,而且对在模拟环境中训练此类机器人大有帮助。因为尽管在这几年,类似的研究还不足以达到这么明显的效果。参考链接:https://www.wired.com/story/meet-curly-the-curling-robot-that-beats-the-pros/来源:wired、新智元











 粤公网安备 44010602004358号
粤公网安备 44010602004358号