人工智能不仅仅是像 ChatGPT 这样的大型语言模型——它是一个庞大的领域,包含相互关联的技术、工具和功能,可在各个领域应用多种多样。
将人工智能视为单一事物可能会掩盖能力、安全性和政策设计等关键维度。如今归因于人工智能的许多问题在大型语言模型(LLM)兴起之前的数字生态系统早期阶段就已经存在。
国家人工智能计划需要将人工智能视为多元的,包括特定行业的战略,并支持基于现实世界用例和采用模式的多种模型类型。
随着像 ChatGPT 这样的大型语言模型 (LLM) 备受关注,如今的人工智能常常被当作一种单一的力量来讨论。但这种框架掩盖的远比它揭示的更多。人工智能并非单一的事物——它是一个由相互关联的技术、工具和能力组成的庞大领域,正在跨领域和特定应用进行开发和部署,这些应用包括分子特性预测、视频超分辨率和多语言语音生成等。
本研究考察并阐释了这些领域和应用。这项研究强调了一个关键现实:人工智能既非单一,也非静态。相反,它包含日益复杂的动态能力,涵盖医疗诊断、物理机器人、游戏代理、图推理等众多领域。这一格局正在快速演变,其结果并非一场单一的革命或单一的智能形式,而是一个层层递进、不断扩展的能力生态系统。
这种多样性不仅对市场至关重要,而且对人工智能战略和治理的各个方面都至关重要。它决定了需要进行哪种测试、如何评估风险,以及各国如何或为何选择监管或采用特定形式的人工智能。将人工智能视为这个多样化生态系统中单一的整体,最终可能会适得其反。本文的其余部分将探讨如何避免这种陷阱:首先,展示人工智能领域和任务的广度;其次,解析这些功能如何映射到实际系统和风险中;最后,讨论将人工智能视为多元而非单一事物后出现的治理和主权战略。
打破多个人工智能
为了理解这种多样性,我们从Papers with Code 的最新 (SOTA)排行榜中抓取了一个开放的 AI 模型数据集。该数据集涵盖了数百个基准测试中的 20,000 多个任务。这些资源来自各种技术论文(例如 arXiv 预印本、AI 会议论文集等)、排行榜(例如SuperGLUE、HELM、Visual Questions answer reasoning)以及相关的 GitHub 代码库。该数据集提供了数千个机器学习和 AI 任务及模型的基准性能。
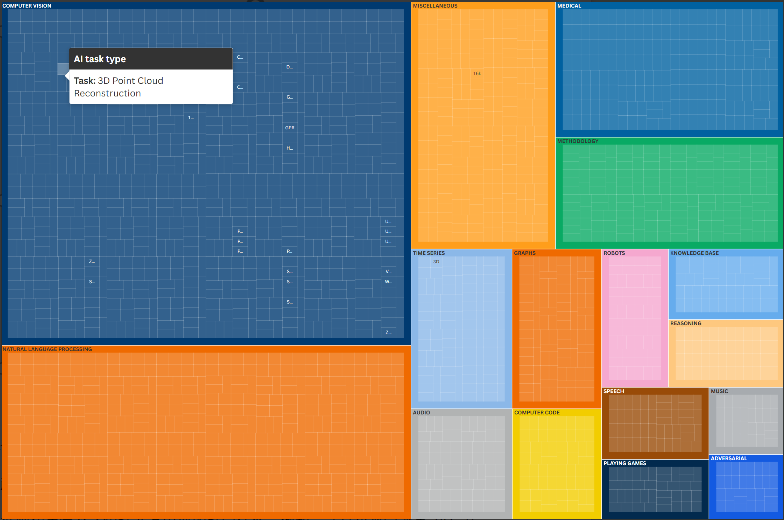
(来源。作者使用 PapersWithCode (2025) 的数据进行计算。注:此树状图基于 PapersWithCode 平台的基准数据,可视化了人工智能发展的分层架构。每种颜色对应一个顶级领域,例如计算机视觉、自然语言处理或机器人技术,而嵌套框则代表每个子领域及其内部的特定任务。例如,计算机视觉涵盖 3D 识别、视频分析和面部检测等领域,而自然语言处理则包含情感分类和实体识别等任务。机器人技术则涵盖轨迹规划和抓取估计。每个部分的大小和密度反映了研究活动的数量和基准的多样性。强调人工智能并非单一的能力,它能够将相互关联的功能具体化,形成一个外部生态系统。)
我们的快照涵盖了现代深度学习时代(2010 年代后),随着基准测试的激增,2015 年之后的覆盖范围更加密集。我们首先从原始数据出发,整理出 AI 领域、子领域和任务的层级结构。这种分类法反映了 AI 能力在广度和特异性方面的演变。表 1 以高层次的形式展示了这一结构,描述了每个领域以及每个领域所需的关键研究和培训。
图 1 进一步展示了更精细的树状图可视化,涵盖了完整分类法中每个领域内的具体子领域和任务,以及每个领域内的研究活动量;该可视化也可通过公共仪表板访问,供进一步探索。其结果是一个自下而上、数据驱动的人工智能进展视图,反映了研究人员实际“在野外”进行基准测试的情况,而非像美国国家标准与技术研究院 (NIST)分类法或欧盟《人工智能法案》大型模型条款那样采用自上而下的模式。

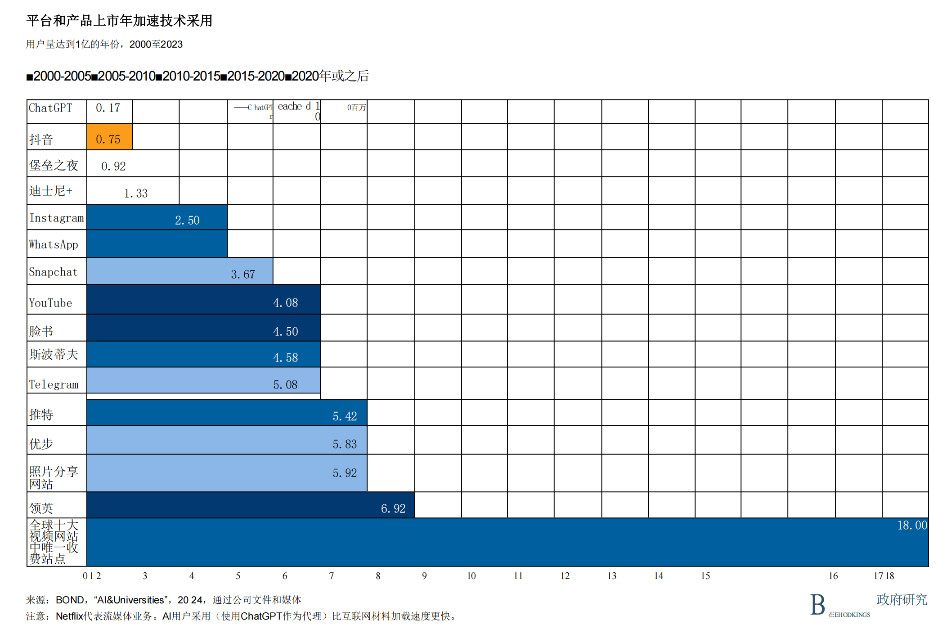
图 1 进一步展示了更精细的树状图可视化,涵盖了完整分类法中每个领域内的具体子领域和任务,以及每个领域内的研究活动量;该可视化也可通过公共仪表板访问,供进一步探索。其结果是一个自下而上、数据驱动的人工智能进展视图,反映了研究人员实际“在野外”进行基准测试的情况,而非像美国国家标准与技术研究院 (NIST)分类法或欧盟《人工智能法案》大型模型条款那样采用自上而下的模式。
除了上面显示的任务多样性之外,模型产品的多样性也在不断增加。即使在领先的提供商中,也已经从单一的通用系统转向较小的专用模型。例如,Meta 的LLaMA 3 系列和 Mistral 的Mixtral 8x7B表明开放模型可以针对企业或特定领域的用途进行调整。Google DeepMind 不仅发布了用于语言的 Gemini,还发布了领域特定系统,例如用于预测蛋白质折叠的AlphaFold和用于天气预报的GraphCast 。阿里巴巴发布了领域特定模型,包括用于语音识别任务的QwenCoder、QwenMath、QwenAudio和用于图像生成的QwenImage。亚马逊的企业模型包括用于商业应用程序的AWS App Studio、用于生成临床记录的AWS HealthScribe和用于机器人交通管理的DeepFleet 。
这些例子强调,人工智能的未来不仅在于扩展通用模型,还在于根据特定功能、成本概况和部署需求开发和定制模型。从这个意义上讲,区分不同类型的人工智能至关重要:所谓的“狭义人工智能”,专门针对一组特定的任务而构建(例如,用于蛋白质折叠的 AlphaFold);以及“通用或生成式人工智能”,它在广泛的数据集上进行训练,以产生灵活的输出(例如,大型语言模型)。目前的发展正朝着两个方向发展——用于领域性能的更窄、更专业的系统,以及用于一般交互的更广泛的生成式模型——这进一步表明,人工智能的发展轨迹是多元的,而非单一的。
多元智能、多种模型、多种策略
树状图(图 1)和 AI 模型的多样性进一步证明,语言模型只是更广泛的 AI 堆栈中的一小部分。视觉系统、控制代理和 3D 姿态估计器与语言性能关系不大,而与物理基础设施、医疗 保健和工业控制关系更大。虽然神经网络的底层构建模块(例如反向传播、梯度下降)在各个领域都很常见,但这并不意味着 LLM 本身就是视觉、机器人或医疗 保健领域进步的驱动力。事实上,大多数自动驾驶或医学成像系统使用的是专门的、针对领域进行调优的模型,而非通用的 LLM,这再次凸显了 AI 方法的多样性。
人工智能在这些领域和功能中体现出的多样性,与人类智能的进化历程相似。视觉感知,包括边缘检测和运动感知,是最古老的认知功能之一,可以追溯到5亿多年前的寒武纪生命大爆发。同样,人类通过海马体等结构所支持的时空建模能力,大约在2亿年前进化而来,并且为许多脊椎动物所共有。
相比之下,语言的适应性要晚得多,估计出现于5万至20万年前,具体取决于我们如何定义符号交流和句法结构。这一历史背景对人工智能至关重要:我们现在与机器“智能”相关的许多任务——感知、空间推理、运动控制——都依赖于语言出现之前就已经存在的进化能力。
基于这种进化的大脑发展,教育心理学家霍华德·加德纳提出了“多元智能”的概念——智能并非单向度的,而是多种属性和技能的集合,这些属性和技能能够形成不同的学习方式。他将智能定义为“一种处理信息的生物心理潜能,这种潜能可以在特定的文化环境中被激活,从而解决问题或创造在特定文化中有价值的产品”。人工智能的多个领域也发挥着类似的作用。加德纳确定了八种不同的智能形式:语言智能、逻辑数学智能、空间智能、音乐智能、身体运动智能、人际智能(通常被描述为社交智能)、内省智能和自然感知智能(对自然的理解)。法学硕士(LLM)显然在人工智能的语言领域和应用领域开展工作,并且在逻辑数学、音乐和视觉领域的应用也日益精通,而其他领域的技术发展则相对滞后。当然,这种类比也有其局限性。生物智能体现在神经元而非硅片中,而语言人工智能则建立在人类已有的语言产物之上。然而,如果自然界的智能是在多维度上进化的,那么以神经元为模型的人工智能又有何不同呢?
尽管人工智能正在通过更具体的能力不断发展,但当今的政策对话往往侧重于大型语言和多模态模型。人工智能的安全性、协调性和治理必须考虑到这种更加多样化的格局。与经过训练以生成文本为目标的系统相比,经过空间推理或蛋白质折叠训练的系统具有截然不同的风险、可供性和评估需求。基于风险的方法应该考虑到这些差异,尽管政策辩论在实践中往往滞后。将人工智能视为以语言为中心的整体,可能会掩盖能力、安全性和政策设计的关键维度。正如互联网学者米尔顿·穆勒 (Milton Mueller)所写,“‘人工智能’不是一项单一的技术,而是由全球无处不在的数字生态系统启用和支持的一组高度多样化的机器学习应用程序。”我们今天归咎于人工智能的治理问题——偏见、错误信息、版权和安全——早在法学硕士学位出现之前就已经在数字生态系统的早期阶段显现出来。人工智能改变的是这些问题的范围:生成系统可能会加速庞大训练语料库中的偏见并大规模传播它们,从而使熟悉的治理挑战变得更加分散和广泛。
跨用户、跨地区、跨职能的 AI 采用
对大型模型的关注反映了生成式人工智能进入公众意识和职场应用的速度。如图4所示,ChatGPT在短短几个月内就拥有了1亿用户,其普及速度甚至超过了Instagram、Facebook甚至iPhone等平台。这种可及性和普及度的急剧上升曲线在技术传播史上是前所未有的。它标志着人们对数字化的基准预期和技术普及时间从数年缩短至数天。
![]()











 粤公网安备 44010602004358号
粤公网安备 44010602004358号