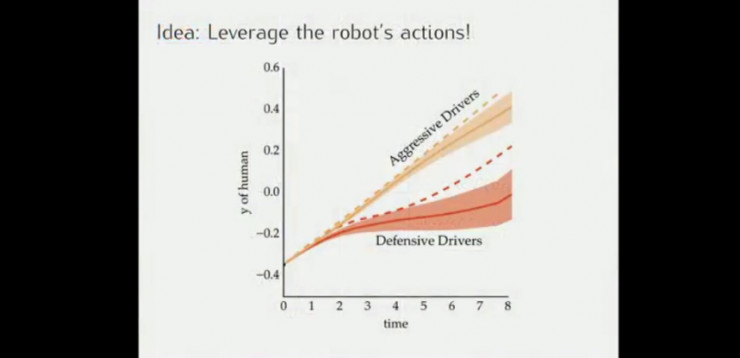

通过对人类司机驾驶轨迹的观察,可以推断出司机的驾驶风格:比较激进或者比较保守,并采取正确的策略,如判断对方是一个保守型的司机的时候,在其前面变道超车对方通常会避让。
像这种情况的激进型司机,无人车只能放弃变道。

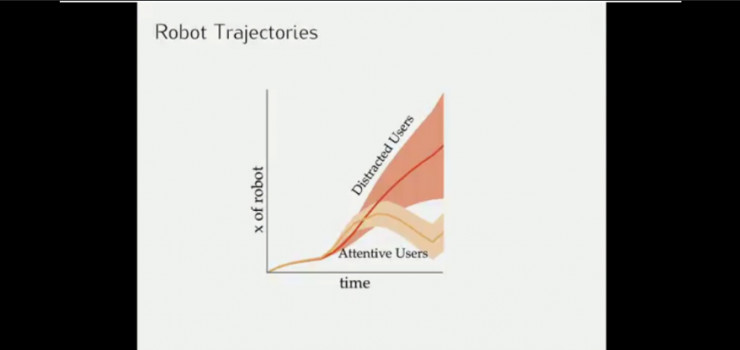
而在十字路口的例子中,无人车需要判断这个司机是否注意其他车辆的动作。
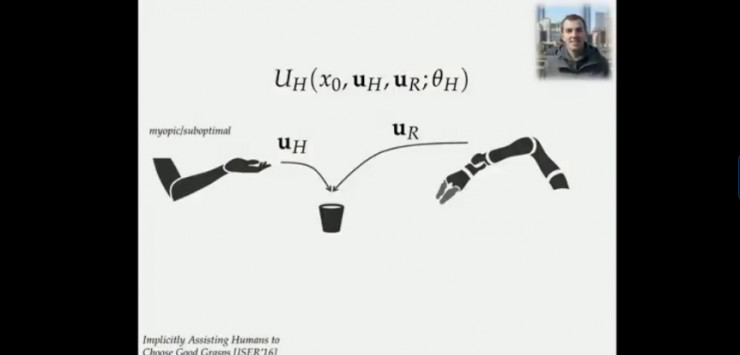
在优化之外的紧急场景的系统协调策略又是怎样的呢?

当仅和最终用户交互的时候,无需考虑两个效用函数,只需要和人类站一边考虑UH最大化即可。

上述讨论的很多都是机器人如何估计人类隐藏参数的研究,另一种方式则是人如何思考与机器人互动中的参数的推断,这方面的研究一直在进行,而且需要机器人有更多的表现力。对于不同人,机器人同样的动作也会产生不同的后果,即便人类无法正确推断机器人行为的时候,至少要让他们知道发生了什么事,你想做的是什么,为什么交互没有取得更好的结果等等。机器人需要注意这个更微妙的影响,因为它决定了人们是否了解机器人正在做什么,是否有信心在执行任务等。
然而我们(设计者)在为机器人指定效用函数的时候做的不怎么样,机器人的奖励值通常具有不确定性,这往往会带来出人意料的结果。

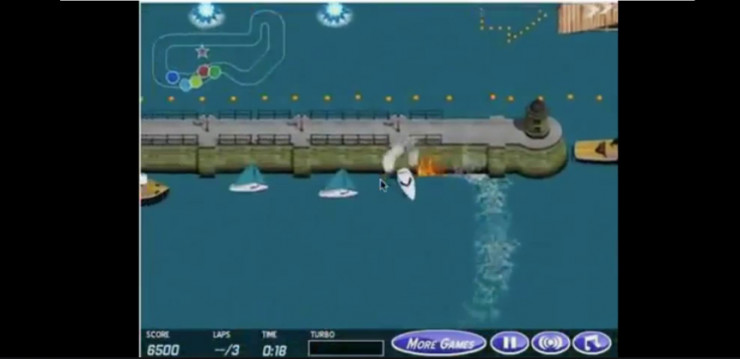
例如在OpenAI的一篇论文中,白色小船的目标是在游戏中获得尽可能多的分,但在这里白色小船却偏离了赛道打起圈子(因为能不断吃到宝箱)。
另一个例子,如果设定一个吸尘机器人的奖励函数是吸尽量多的灰尘,那么机器人会不会在吸完灰尘后把手机起来的灰尘倒出来,然后继续吸尘以达到最大的奖励值?
又或者,像迪士尼动画片米奇用魔法教一把扫把帮其挑水,最后这把扫把不断挑水(获得最大奖励值)把整个屋子给淹了一样;
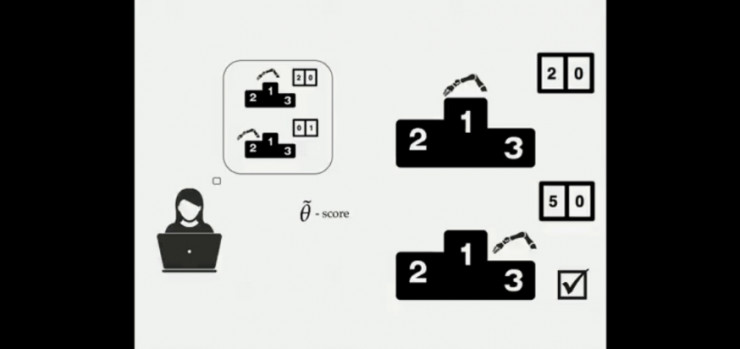
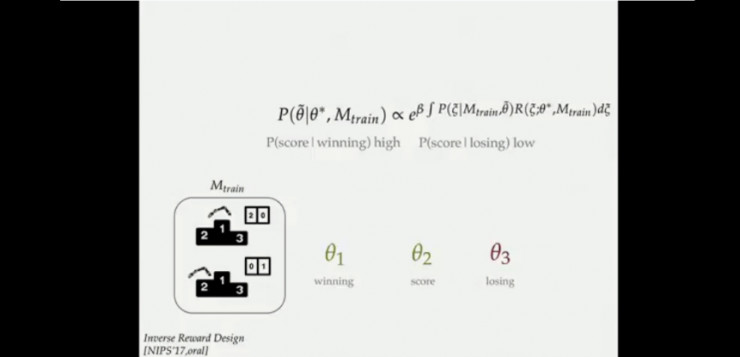
让我们来分析一下这是如何产生的。例如小船游戏的例子,当设置得分为奖励值,当机器发现有两个策略:1)排名第一但仅获得20分;2)排名靠后但能获得50分,机器人选择的是后者。
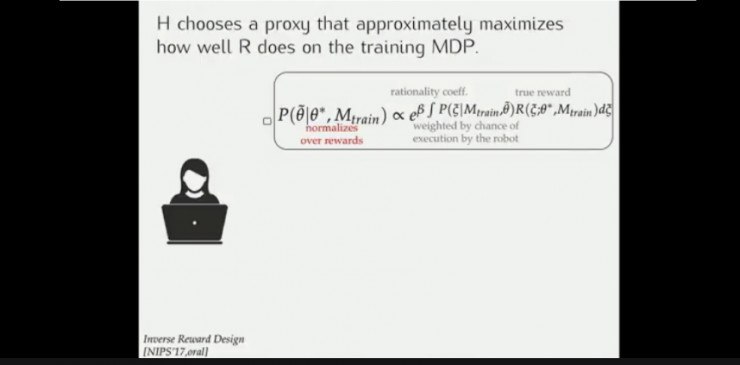
这样,设计者需要改变奖励值(找到真正的奖励值)以使得机器人按预定目标进行决策,或者让机器人能够推测到设计者的真正意图。但二者均有不足之处。
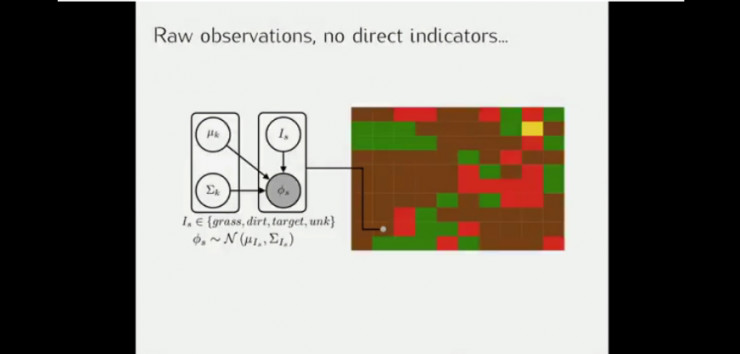
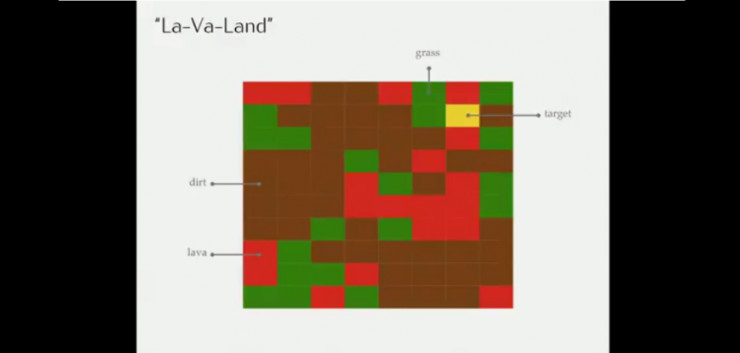
另一个包含草地、灰尘、熔岩和最终目标的导航场景的例子。
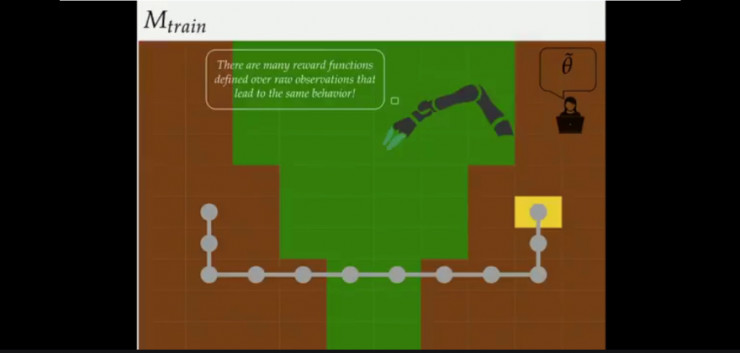
假设训练时的状态,奖励函数是尽可能少走草地得分越高的话,结果会如上图所示(此时没有出现熔岩)。
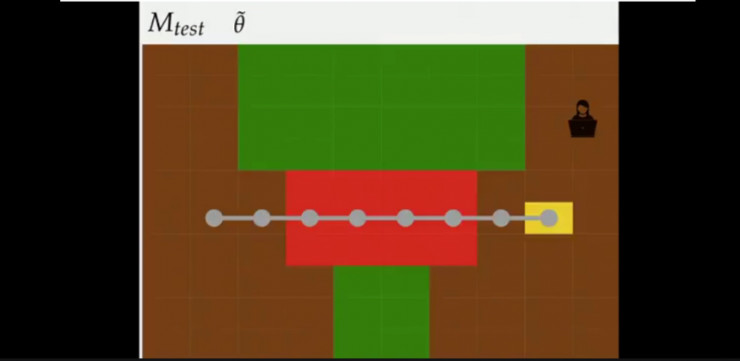

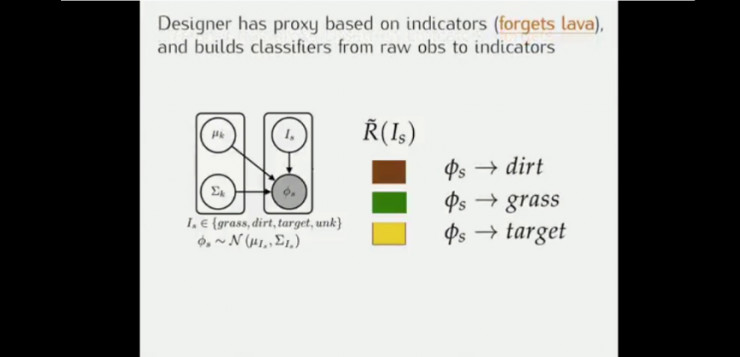
策略1:设计师有基于指标的指示器,并建立从原始观察值到指标的分类器,此时将训练的模型放到有岩浆的例子中时,机器人往往会越过岩浆到达终点(并非想要的结果)
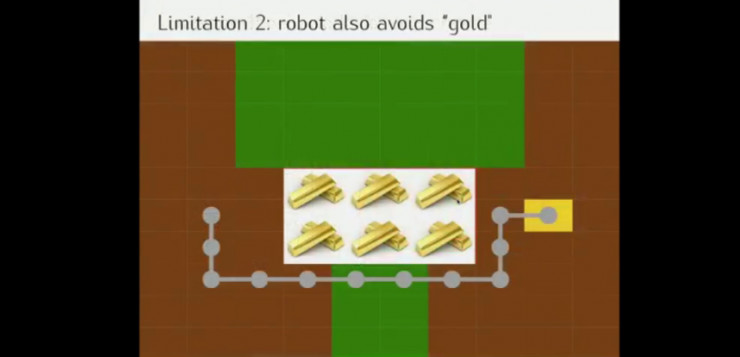

策略2:而如果设定反向激励,机器人会对训练时未出现的元素敬而远之,机器人不知道岩浆是好鸡还是怀,也可能如上图所示错过“金矿”。

通过以上例子,说明需要在训练环境的背景下对特定的奖励进行观察找到真正的奖励,而在执行中人类的指导则是找到真正奖励的关键(如迪士尼动画片中,米奇让扫把停止打水)。

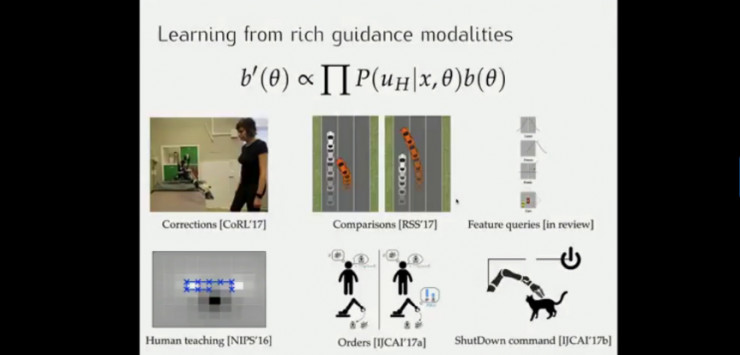
这样,机器人可以从从丰富的指导模式中学习。
简单来说,如果机器人能够理解它可能对人类情绪造成的影响,就可以更好地进行决策,并在更广泛的领域于人类更有效进行协作,给我们生活带来更多便利与惊喜。











 粤公网安备 44010602004358号
粤公网安备 44010602004358号